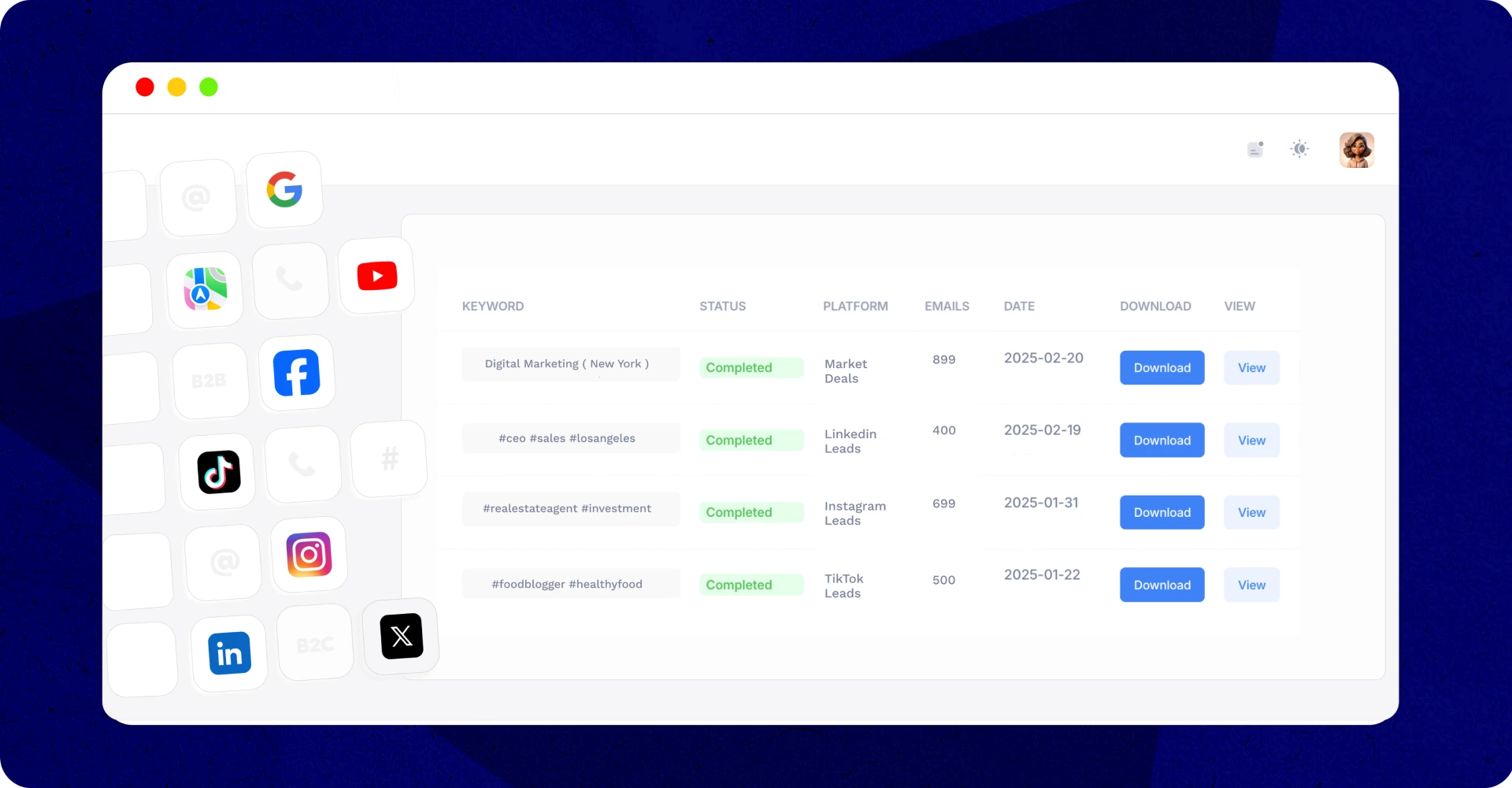

Unlock Leads from 11+ Platforms with Ease
Our all-in-one scraper helps you extract valuable contacts from multiple sources, making lead generation effortless.
- LinkedIn – Find leads by job title, industry, and location to connect with the right professionals.
- Local Businesses – Use our Google Maps scraper to collect contact details for targeted outreach.
- TikTok – Gather emails and user data through specific hashtags for precise prospecting.
- Facebook Groups – Identify potential leads in niche communities and industry-related discussions.
- B2B Prospecting – Access company emails to reach decision-makers directly.

Any Questions?
Our Real Estate Email Scraper is a powerful tool that extracts emails and contact details from publicly available sources. Simply enter the state and the city and our scraper will collect leads for you.
Yes! You can filter leads by location and by using industry-specific keywords. Whether you’re looking for buyers, sellers, or investors, our scraper ensures you connect with the right audience.
There’s no limit! Depending on the search criteria you set, you can collect thousands of real estate leads in just hours, helping you scale your outreach quickly.
All scraped leads are available for download in a structured CSV format, making it easy to integrate with your CRM, email marketing software, or sales outreach tools.
Yes! Our tool only collects publicly available data and complies with all DMCA, CFAA, and data protection regulations, ensuring a secure and ethical lead generation process.
The process is fast and efficient. Depending on your search parameters, you can generate a list of targeted leads within minutes to a few hours.
Absolutely! Our scraper collects both emails and phone numbers when available, giving you multiple ways to connect with potential clients.
Not at all! Our tool is user-friendly—simply sign up, enter your search criteria, click start, and download your leads with ease. No coding or technical setup required.
Our tool extracts leads from multiple sources, including LinkedIn, Google Maps, TikTok, Facebook Groups, and other public databases relevant to real estate professionals.
By providing instant access to targeted, high-intent leads, our scraper helps you reach buyers, sellers, and investors more efficiently. This means more conversions, less wasted time, and a stronger pipeline of opportunities.