




Boost Your Lead Generation Across 11+ Platforms
Twitter is just the start. Our all-in-one tool lets you tap into endless opportunities across multiple platforms.
- LinkedIn: Refine your search by job titles, industries, and locations to discover valuable business leads.
- Google Maps: Use our Google Maps scraper to effortlessly gather contact info for local prospects.
- TikTok: Harvest emails and data through hashtags for precise and effective targeting.
- Facebook: Connect with contacts in niche groups and ongoing discussions to find the right prospects.
- B2B Prospecting: Gain access to company emails and reach out directly to decision-makers.
Any Questions?
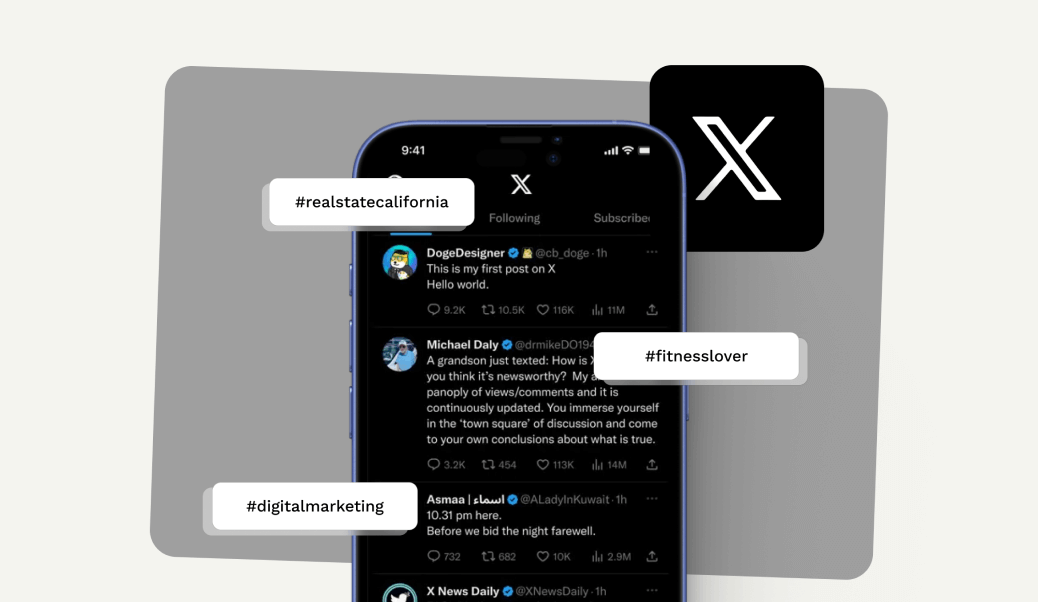
A Twitter email scraper is a tool that automatically collects emails and other contact information from Twitter X users based on specific keywords, hashtags, or profiles. It helps you build a targeted email list quickly and efficiently by extracting data from public Twitter profiles.
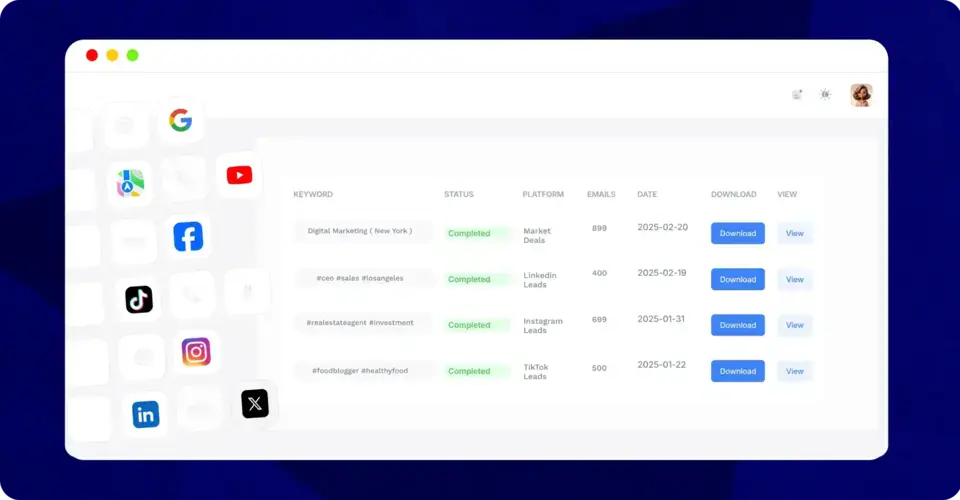
Using our scraper is simple! Just sign up, enter relevant keywords or hashtags, click “Start Scraping,” and let the AI-powered tool gather your leads. Once done, you can easily export the contacts to a CSV file for use in your marketing campaigns.
Yes, you can scrape emails from public Twitter profiles. The tool works by collecting publicly available data, ensuring all information is legally sourced and compliant with privacy laws.
Absolutely. Our tool is DMCA and CFAA compliant, following strict data protection regulations. It only gathers publicly available data from Twitter X, ensuring a secure and ethical lead-generation process.
Yes, the scraper is versatile and can be used for both B2B and B2C lead generation. Whether you’re targeting businesses or individual consumers, our tool helps you collect the right leads.
You can start generating thousands of leads in just a few hours. Our scraper works efficiently, allowing you to quickly build a high-quality email list and start engaging with your prospects.
You can filter your target audience using keywords, hashtags, industry-specific terms, or location-based data. This allows you to find users who are most likely to be interested in your product or service.
Yes, once your leads are scraped, you can easily export them into a CSV file, ready to be imported into your CRM, email marketing tool, or any other software you use to manage your contacts.
Our AI-powered tool suggests high-performing keywords and hashtags that are likely to generate quality leads. This takes the guesswork out of finding the best search terms, saving you time and effort.
Yes, our tool supports lead scraping across 11+ platforms, including LinkedIn, Google Maps, Facebook, TikTok, and more. This multi-platform approach helps you expand your reach and connect with leads from various online sources.