Instant Data Scraper Review 2025: Why I Switched After 6 Months of Daily Use

Six months of daily scraping taught me exactly where Instant Data Scraper works, and where it completely falls apart. This free Chrome extension caught my attention because it promised hassle-free data extraction without coding or subscriptions. For someone pulling leads and running market research daily, the idea of grabbing 1000 records at a time sounded perfect.
The extension uses AI to automatically spot and extract data from web pages, which makes it surprisingly simple for both beginners and experienced users. Those first few months were solid. The pagination feature handled multi-page scraping well, and exporting to Excel or CSV was straightforward. But after months of consistent use, the cracks started showing. Hard.
Here’s the reality: Instant Data Scraper can only extract one table per page. That’s a serious problem when you’re working with complex sites that have multiple data sets.
After digging through user reviews and testing alternatives, I realized my frustrations were pretty common. Sure, people love the simplicity and free access. But plenty of others hit the same walls I did when trying to scale beyond basic projects. The fact that there are no premium plans initially seemed like a win. Turns out it actually means limited development and support.
This review breaks down exactly how I used Instant Data Scraper daily, what worked, what didn’t, and why I eventually had to switch to something more reliable. If you’re considering this tool for serious lead generation or data collection, you’ll want to know what you’re getting into, and how I ultimately found a better solution with IGLeads, which solved most of the bottlenecks I ran into.
What Is Instant Data Scraper and Why I Chose It Initially
After testing various data extraction tools, I settled on Instant Data Scraper, a Chrome extension built by Web Robots, a Lithuania-based company founded by Paulius Jonaitis and Tomas Vitulskis. With over a million users and a 4.9-star rating in the Chrome Web Store, the numbers looked solid for a free tool.
Free Chrome Extension with AI-Powered Detection
What caught my attention was how different Instant Data Scraper’s approach felt compared to other tools. Instead of forcing you to build templates or write site-specific scripts, it uses heuristic AI to automatically analyze HTML structure and detect data patterns on any webpage. This makes it surprisingly flexible across different types of sites.
The AI tries to predict which data matters most on a page, then highlights what it thinks is the main dataset, product listings, search results, directory entries, whatever’s there. This meant I could extract structured data without creating custom scripts for every new site I wanted to scrape.
The completely free access sealed it for me. Unlike other tools that tease you with limited free plans, Instant Data Scraper gives you everything without asking for a credit card. Perfect for testing whether web scraping could actually improve my lead generation without any upfront commitment.
What I like: The AI detection works well on standard table layouts, and the zero-cost entry makes it risk-free to try on different projects.
No-Code Setup for Beginners
Setting up Instant Data Scraper requires zero programming knowledge. The interface is pure point-and-click. You just select the data elements you want to scrape. Even if you’ve never touched code, you can figure this out.
The setup process takes minutes. Install from Chrome Web Store, go to your target site, click the extension icon. The AI automatically detects tables and lists, then presents them for extraction. You can start pulling data immediately instead of spending hours learning complex tools.
The interface lets you preview data before exporting, clean up columns, and choose exactly what you need. For someone handling multiple data collection tasks daily, this streamlined workflow saved significant time compared to manual copy-pasting or wrestling with technical frameworks.
Initial Use Cases: Lead Gen, Market Research, Listings
My main use case centered on lead generation, pulling contact information from business directories and professional networks. The tool handled up to 1000 records, which fit perfectly with my typical campaign sizes.
Beyond lead gen, I found it valuable for market research. Extracting product prices, descriptions, and competitor data from e-commerce sites gave me actionable insights without the manual tedium. The ability to scrape search engine results for SEO research and competitor analysis was particularly useful.
Listings data became another strong use case. Whether I needed real estate information, job postings, or product catalogs, the tool handled structured data efficiently. When monitoring competitor pricing strategies, I could quickly export everything to Excel or CSV formats for analysis.
The extension works best when extracting data from listing pages with clear tables. It’s ideal for pulling specific items like prices, business names, email addresses, phone numbers, and titles. This capability proved especially valuable for building targeted outreach lists without manual data entry.
Bottom line: For basic lead generation and market research, Instant Data Scraper delivered exactly what I needed: fast, simple data extraction without technical barriers or costs.
How I Used Instant Data Scraper Daily for 6 Months
Over six months of daily use, I developed a pretty solid workflow with Instant Data Scraper. The extension saved me hours of manual copy-pasting, though it definitely required some tweaks to work reliably.
My Daily Scraping Routine
Here’s exactly how I approached each scraping session:
- Navigate to the target page: Usually business directories or product listings where I needed contact data or pricing info.
- Click the extension icon: This triggers the AI analysis. The tool scans the page structure and highlights what it thinks are the main data tables.
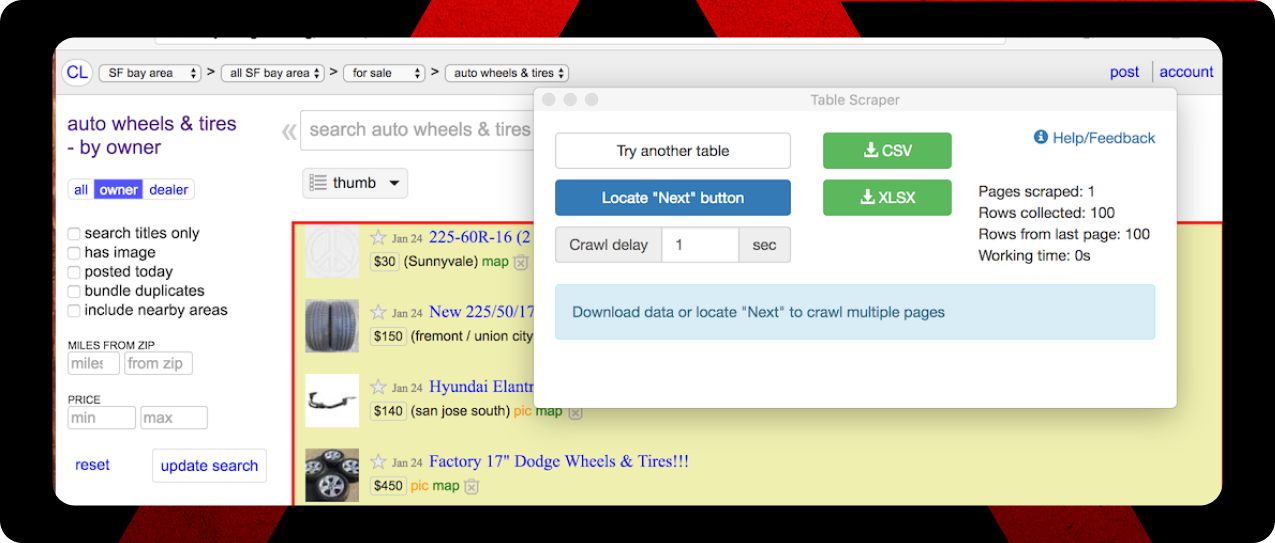
- Pick the right table: Sometimes the AI nails it on the first try. Other times I had to click “Try another table” to find the dataset I actually wanted.
- Set up pagination: For multi-page results, I’d click “Locate Next button” so it could automatically move through pages. This worked great when it worked.
- Adjust crawling delays: I learned to set delays between 2-10 seconds to avoid looking like a bot. Slower is better if you want to avoid getting blocked.
The tool’s ability to wait for dynamic content to load was actually pretty impressive. JavaScript-heavy sites that would break other scrapers usually worked fine here.
What Actually Worked Well
The pagination feature was genuinely useful once I got it configured properly. Set it up right, and Instant Data Scraper would click through dozens of pages automatically, collecting everything without me having to babysit it.
For sites with infinite scroll, I could just check the box and let it run. Pretty smooth.
Exporting was dead simple. One click and I had my data in CSV or Excel format. I usually went with Excel because it handled special characters better, and the formatting stayed cleaner.
For basic tabular data from business directories or e-commerce sites, the export quality was solid. Clean columns, proper formatting, no major data corruption issues.
The Data Cleaning Reality
Even with AI detection, raw scraped data always needed cleanup. Every single time.
Common issues I dealt with:
- HTML code fragments showing up in text fields
- Inconsistent date and currency formats
- Generic column headers like “Column 1” and “Column 2”
- Irrelevant columns full of website navigation elements
I ended up building Excel macros to handle the repetitive stuff. Saved me probably 30 minutes per dataset. Not elegant, but it worked for the volume I was handling.
Working Around Blocks and Limits
The first few months were smooth sailing. Then websites started recognizing and blocking my scraping attempts.
I started rotating proxy servers to mask my IP address. This helped me get around basic IP-based blocks, especially when scraping at higher volumes. The key was making requests look like they came from different users in different locations.
I also learned to respect robots.txt files and add random delays between requests. Basic courtesy, but it kept me under the radar on smaller sites.
For the really aggressive anti-scraping setups, I had to resort to manual scraping in smaller batches. Frustrating, but it worked.
Bottom line: The daily workflow was manageable for small to medium projects, but the manual interventions and workarounds started adding up. When you’re scraping thousands of records regularly, those little friction points become major time drains.
Where Instant Data Scraper Fell Short Over Time
What started as minor annoyances gradually turned into serious workflow killers. As my scraping volume increased and projects got more complex, Instant Data Scraper’s limitations became impossible to ignore.
Manual Pagination Kills Productivity
The biggest problem? Pagination handling is completely manual. For large-scale projects, you’re stuck clicking through every single page transition yourself. This process is painfully slow when you’re trying to scrape thousands of records.
Each pagination sequence requires clicking the Next link and babysitting the entire process. No automation. No background processing. Just you, your browser, and hours of repetitive clicking. If the “next” button isn’t clearly visible or positioned differently than expected, the scraper often fails completely.
The tool works fine for smaller projects, but anything beyond 1000 records becomes a serious time sink. I’d often find myself monitoring the browser for hours during larger extractions, which defeats the entire purpose of using an automated tool.
Zero API or Scheduling Options
Here’s what really frustrated me: there’s absolutely no way to automate recurring scraping tasks. No API access. No scheduling. No background processing. Every single scrape requires manual setup and monitoring.
For daily lead generation, this meant starting every scrape job by hand, even for the same sites I was hitting repeatedly. You can’t schedule overnight scrapes or integrate with other tools. Every extraction eats into productive work time because you have to actively manage the process.
This became a major bottleneck when I needed to update datasets regularly. Same manual setup. Same monitoring. Same time investment, every single time.
Single Table Limitation Creates Bottlenecks
One of the most restrictive problems: Instant Data Scraper can only extract one table structure per page. If you’re working with complex sites that have multiple data tables, you’re running separate scraping sessions for each one.
The extension struggles with:
- Multiple tables on the same page
- Complex web page structures
- Dynamic JavaScript-rendered content
- Pages requiring authentication
- Nested table layouts
I hit this constantly when scraping product pages that separated specs, pricing, and reviews into different tables. Each section required its own extraction process, making comprehensive data collection incredibly tedious.
No Support When Things Break
Six months of usage taught me that you’re pretty much on your own when issues arise. Community forums exist, but response times are inconsistent at best. For professional use, this creates real problems.
When sites started blocking me or extraction errors popped up, troubleshooting fell entirely on me. The community-driven Google group offers some help, but you can’t rely on timely responses for urgent projects. Paid services offer dedicated support. This doesn’t.
The free model that initially seemed attractive actually works against you here. Without premium plans generating revenue, there’s little incentive for substantial updates or improvements. The lack of built-in proxy support makes this even worse, especially when scraping larger websites that actively block scrapers.
Bottom line: What works for small, occasional scraping projects becomes a serious productivity drain when you need consistent, large-scale data extraction.
What Other Users Are Actually Saying in 2025
After months of hitting the same walls, I started digging through Chrome Web Store reviews, Reddit threads, and tech forums to see if my experience was typical. Turns out, it absolutely was. User feedback in 2025 tells a pretty clear story about where this tool works and where it doesn’t.
The Love: Simple Scraping That Just Works
For basic scraping jobs, people genuinely love this tool. The praise is consistent when Instant Data Scraper works, it’s fast and intuitive. One user captured it perfectly: “I was able to create a custom recipe within 5 minutes without any reading of documentation. The automatic paging worked nicely as well”.
The time-saving element resonates with a lot of users: “Once you get the hang of it, you can pull data from a page in minutes, which would otherwise take hours of manual copy-paste”. The AI detection gets solid props too, with users calling it “on point” and praising how it “automates the entire scraping process like a pro”.
The Frustration: When It Breaks, It Really Breaks
But here’s where it gets messy. Technical issues are rampant, and the inconsistency drives people nuts. Sometimes it works perfectly, sometimes it completely fails or only grabs partial data. One frustrated user didn’t hold back: “Such a time waste. Most of the time didn’t work and sometime it hang the browser… Its better to do everything manually. 110% Time Waste”.
The limitations I experienced aren’t unique. Users consistently report that the extension “struggles with complex websites and multiple tables” and depends heavily on finding a visible ‘next’ button for pagination. Dynamic sites and JavaScript-heavy content? Forget about it.
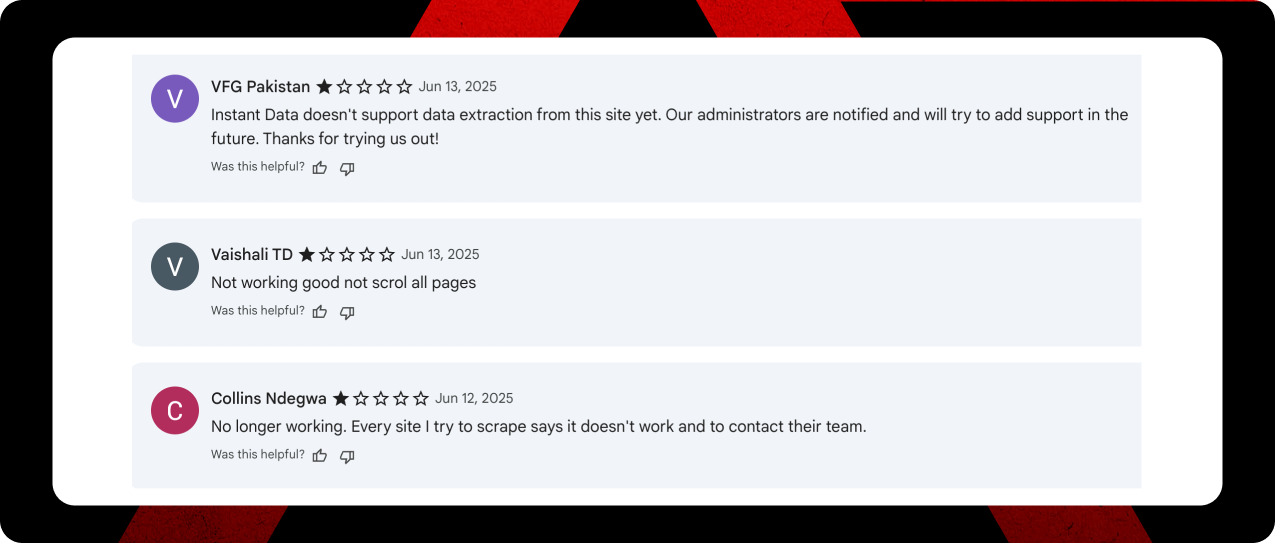
The Bait-and-Switch Problem
Here’s the real kicker, and something I didn’t experience during my testing. Users are getting hit with unexpected restrictions: “Too limited you can scrape only 3 pages. Requires paid subscription to try scraping anything worth scraping”. Another user put it bluntly: “Used to be great. However this is no longer a free tool after it limited the URL list scrape into only three web pages for the free version”.
This creates a nasty surprise for users who expected a completely free solution. Since the extension only handles the scraping part, you still need additional tools for lead management and outreach campaigns: Costs that add up fast when you’re trying to build a real workflow.
Bottom line: The user feedback confirms what I experienced. It is great for simple jobs, but frustrating limitations and inconsistent performance make it unreliable for serious data collection.
Why I Switched to IGLeads (and What Changed)
After six months of fighting with Instant Data Scraper’s limitations, I made the jump to IGLeads. The difference was immediate and frankly, pretty dramatic.
Cloud Scraping That Actually Works While You Sleep
The biggest game-changer? IGLeads runs in the cloud. While Instant Data Scraper required me to babysit my browser for hours, IGLeads keeps scraping Instagram profiles even when my laptop is closed. The system emails me when my lead list is ready, which means I can actually get other work done.
This automated approach solved my biggest headache with Instant Data Scraper: The constant manual intervention. With IGLeads, I set my parameters, hit start, and walk away. No more sitting around watching progress bars.
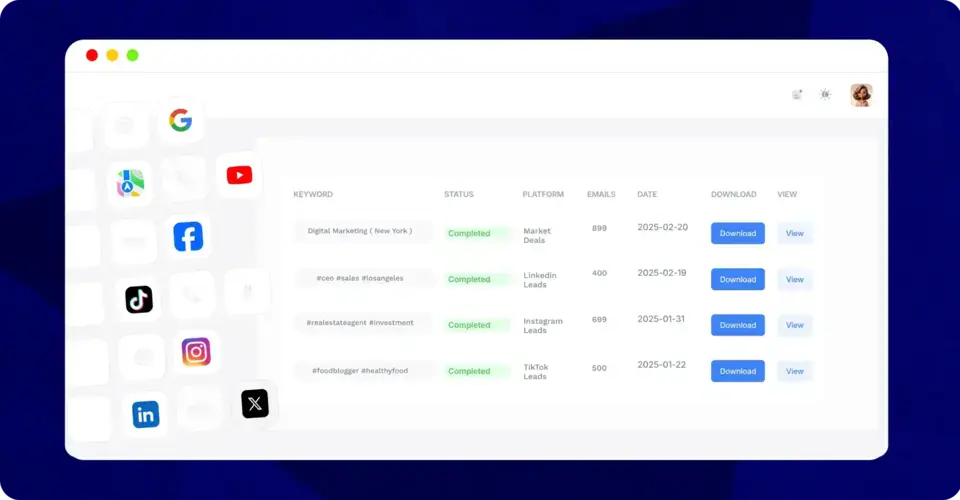
Multi-Platform Scraping Changes Everything
Being stuck with one table per page was killing my productivity. IGLeads throws that limitation out the window with support for 11+ platforms. I can now pull leads from Instagram, Facebook, LinkedIn, Twitter, TikTok, YouTube, Google Maps, and more. All from one dashboard.
This multi-platform capability opened up lead sources I never had access to before. For my specific market, Instagram hashtag scraping and location-based targeting have been incredibly valuable. Same with pulling LinkedIn profiles directly from search results.
Speed and Scale That Actually Matters
The difference in scale is night and day. IGLeads delivers thousands of targeted leads in just a few hours, compared to the painfully slow manual process I was dealing with before. Even large scraping jobs typically finish in under 8 hours: A massive improvement.
The data quality is cleaner too. IGLeads exports are structured and ready for immediate CRM import, which cut my post-processing time significantly.
Pricing: Worth Every Dollar
Going from free to paid initially felt like a step backward. But IGLeads pricing structure quickly proved its value. The starter plan runs $59/month for 10,000 emails, and annual plans save up to 47%.
Unlike credit-based systems that nickel and dime you, IGLeads offers flat-fee pricing with unlimited email extraction on higher tiers. When you factor in the time saved and better lead quality, it’s actually more cost-effective than the “free” alternative.
Bottom line: Switch to IGLeads and see the difference yourself. After testing both tools extensively, the investment pays for itself through improved efficiency and lead quality alone.
Frequently asked Questions
Yes, Instant Data Scraper is a completely free Chrome extension. However, some users have reported limitations on the number of pages that can be scraped in the free version, which may require a paid subscription for more extensive scraping tasks.
The main limitations include manual pagination for large jobs, inability to scrape multiple tables on a single page, lack of API or automation support, and no real-time technical support or frequent updates.
While Instant Data Scraper is free and easy to use for basic scraping tasks, paid alternatives like IGLeads offer more advanced features such as automated cloud scraping, multi-platform support, and the ability to handle larger volumes of data more efficiently.
The legality of data scraping depends on various factors. Scraping publicly available data is generally considered legal, but it’s important to respect website terms of service, copyright laws, and data protection regulations. Scraping private or protected data without authorization can be illegal.
Instant Data Scraper may struggle with complex websites, multiple tables, and dynamic JavaScript-rendered content. It works best with simple, structured data tables and may require manual intervention or alternative solutions for more complex scraping tasks.
There are several free data scraping tools available as alternatives. Some options include ParseHub, Octoparse, and Scrapy. These tools offer various features for users looking to scrape data without incurring costs.